간만의 포스팅 입니다.
올해 EMC 에서 새로 출시되었던 VNX MCx (이하 MCx) 에 대해 한번 알아보겠습니다. 이 문서는 http://www.emc.com/collateral/white-papers/h12090-emc-vnx-mcx.pdf 에 있는 화이트페이퍼의 번역본입니다.(전부는 아니고…) 번역과 동시에 제가 별도로 첨부할 내용이 있다면 따로 적도록 하겠습니다. 이 문서에서는 MCx 라고 기술을 하지만 일반적으로는 VNX2 라고도 불립니다.
MCx 설계목적는 다음과 같습니다.
- 멀티 프로세서 아키텍처
- Active/Active 지원
- 성능향상과 확장성
- 메모리 사용 효율화
첫번째로 변경된 점은 이제서야 멀티코어 프로세서를 제대로 지원한다는 것입니다. VNX1 과 CX 모델은 싱글 스레드를 처리하도록 설계된 Flare OS 를 사용하고 있었고, FLARE OS 의 몇가지 기능들은 Core 0번에서 처리되도록 되어있었습니다. 그리고 I/O 가 발생하면 Core 0번에서 먼저 처리하고 다른 Core 로 넘기게 되는 모델이였습니다. 즉 Core 0번이 일종의 게이트키퍼 역할을 하게 되었습니다.
각각의 Core 에서 다른 종류의 기능들을 수행함에 따라 Core 가 낭비되는 경우는 줄었지만, Core 0번에 병목이 발생할 경우 시스템의 전체 성능이 영향을 주게 되었으며, Core 갯수를 증가시키더라도 대다수의 스레드들이 Core 0 ~ 5번 정도에서 처리됨에 따라 Core 의 낭비가 심했었습니다.
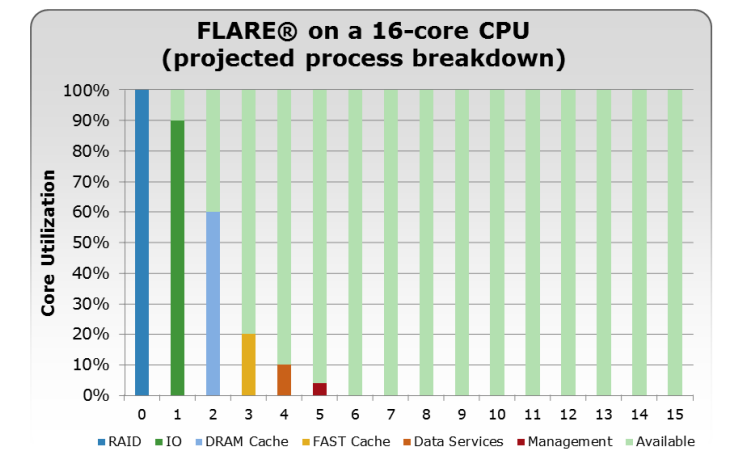
자신이 가진 모든 코어를 동시에 완벽하게 사용할 수 있는 시스템은 없습니다. 예를 들어 4개의 코어를 풀 가동하더라도 싱글코어에서 프로그램을 처리하는 속도보다 4배 빠르지 않습니다. 성능은 프로세서의 개수에 비례하지 않기 때문인데, 암달의 법칙 이라고 하기도 합니다. 암달의 법칙을 간단히 설명하면 이렇습니다. 많은 프로세스가 있다 하더라도 반드시 순차적으로 처리가 되어야 하는 작업이 있기 마련인데, 이러한 작업들로 인해 전체의 작업시간이 지연된다는 것이죠. 다시 한번 풀면
A, B, C, D 라는 4개의 작업이 있는데 이 작업들이 4개의 Core 에서 각각 실행될 수 있다면 전체적인 처리속도는 4배가 될 것입니다. 그렇지만 A,B,C,D 가 반드시 순차적으로 실행되어야 하는 작업이라면? 4개중에 하나의 프로세스만 사용하게 되겠죠. 작업들을 전부다 병렬화 할 수 있으면 좋지만, 병렬화 시킬 수 없는 부분이 있기 때문에 프로세스가 늘어나더라도 늘어난 만큼의 성능향상이 되지 않기 때문입니다. 그리고 작업들을 코어별로 분산시키는데도 많은 시간이 소요되죠.
Core affinity
MCx 의 컨셉중 하나는 Preferred Core 입니다. 모든 프론트 엔드와 백엔트 포트는 각각의 Preferred Core 와 Alternating Core 를 가지게 됩니다. 프론트엔드의 경우, 시스템에서는 프론트엔드 호스트에서 요청한 작업들을 최대한 Preferred Core 에서 처리할려고 하게 됩니다. 다른 Core 로 넘기게 될 경우 Core 간 Cache 와 Context 를 스왑해야 하는 과정 들이 필요한데 해당 과정들이 시스템의 성능에 영향을 미치기 때문입니다. 백엔드의 경우는 모든 Core 가 모든 Drive 에 접근이 가능하기 때문에, 이러한 스왑 과정이 필요하지 않습니다. Preferred core 가 busy 한 경우에는 alternate core 가 사용되게 됩니다.
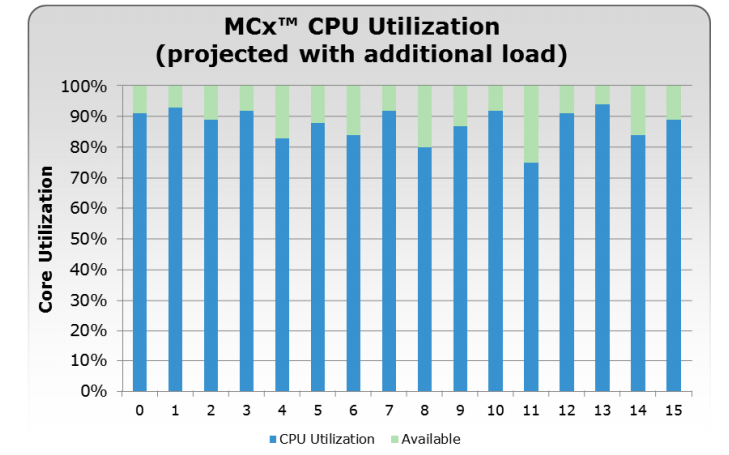
조금 덜 Busy 한 프로세서에서는 non-host I/O 나 스토리지 자체적으로 발생하는 I/O 를 처리하게 됩니다. Disk rebuild 나 proactive copy, sniff verify, disk zeroing 등의 Backend I/O 작업들은 호스트의 I/O 에 영향을 미치지 않습니다. 이러한 컨셉으로 인해 MCx 는 FLARE 보다 많은 성능향상을 이룰 수 있게 되었습니다.
또한 I/O 가 증가할 경우 MCx 는 사용가능한 다른 Core 들로 작업을 자동으로 분산시키기 때문에, 시스템의 모든 Core 를 효율적으로 사용할 수 있습니다. 다음과 같이 말이죠!
Stack components
멀티코어 기술이 나오기 전에 나왔던 FLARE OS 는 CPU 들의 작업 스케쥴링을 다이나믹하게 처리할 수 있도록 설계되지 않았습니다. FLARE 는 RAID 기술들이 나오기 시작할 때 탄생하였고, RAID 나 Caching 등을 처리하기 위한 Midrange 스토리지의 엔진이 되었습니다. 시간이 흘러 Pools, Compression, Auto-Tiering, Snapshot 등의 기능들이 FLARE OS 에 추가되었습니다. 이 문서에서는 이러한 기능들을 “Data Services” 라고 표현합니다.
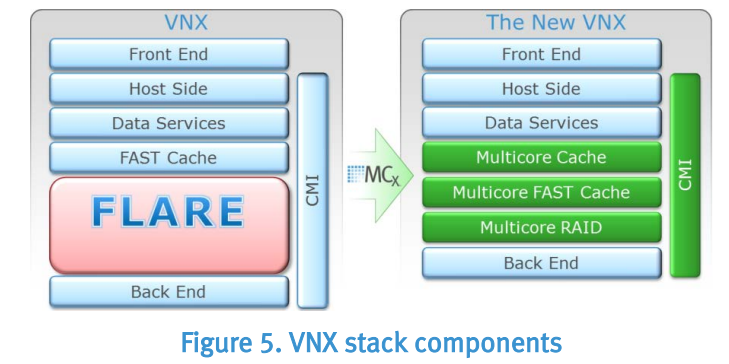
그러나 Multi core 기술들이 나오기 시작하면서 MCx 에는 Multicore RAID, Multicore Cache, Multicore FAST Cache, Symmetric Active/Active, Multipath Communication Manager Interface 등의 기술들이 개발되어 포함되었습니다. 이러한 Stack 의 순서변화로 인하 아키텍처에 큰 변화가 생겼습니다. FLARE Stack 에서는 모든 I/O 는 DRAM CAche 가 있는 FLARE 레이어에 도달하기 전에 Fast Cache 레이어의 맵을 지나가게 됩니다. 이러한 특성으로 인하여 Write Ack 를 호스트로 보내는데 지연이 발생하게 되었고, 쓰기 성능에 저하가 있었습니다. MCx 에서는 모든 Write 는 바로 DRAM Cache 로 도달하게 되어, 응답시간이 감소하였으며, 그 결과 Host Write 는 DRAM Cache 에서 미러링 되고 보호되어, 성능향상을 가져오게 됩니다. 이러한 변화로 인해 Symmetric Active/Active 도 가능하게 되었습니다.
Multicore Cache
일반적으로 SP Cache 라고 하며, MCx 에서는 VNX 의 Storage Process(이하 SP) 의 DRAM 을 최적화하여 읽기/쓰기 성능을 향상시켰습니다. Multicore Cache 는 FLARE 에서는 FLARE Drive 의 일부였지만, MCx 에서는 별개의 컴포넌트로 동작합니다. Cache 는 다른 컴포넌트들과 연계되어있고, VNX 의 모든 소프트웨어 레이어에 Write Caching 을 제공하게 됩니다. 그리고 다음과 같은 기능을 지원합니다.
- Multicore CPU scaling
- Symmetric Active/Active 지원
- Adaptive and automatic performance self-tuning
Adaptive Cache
FLARE 에서는 Cache 가 3개의 영역으로 이루어져 있습니다. Read Cache 와 Write Cache 그리고 Mirrored 되어있는 Peer SP 의 Write Cache. 이 영역들에는 OS Overhead 에 대한 것은 포함되어있지 않습니다. FLARE OS 에서 Read Cache 는 주로 Prefetching 을 위해 사용됩니다. Read Misses 가 발생할 경우 데이터가 디스크로부터 Read Cache(1) 로 올라오게 됩니다. Read Hit 가 된다면 다음부터는 Read Cache 로부터 데이터를 읽을 것입니다.(2)
Write Cache 도 크게 다르지는 않습니다만, “dirty” 로 마킹된 Write I/O 는 예외입니다. Cache 내에 데이터가 있는 상태에서 write 가 발생할 경우 dirty page 에 overwrite 하게 되며(3), Peer SP 의 Cache 로 Mirrored(4) 됩니다. 이때는 LRU(Least Recently Used) 에 의하여 가장 오랫동안 사용되지 않은 cache page 가 disk 로 de-stage(flushing)(5) 됩니다. de-stage 된 cache page 는 peer SP 의 write cache 에서도 삭제(6)됩니다.
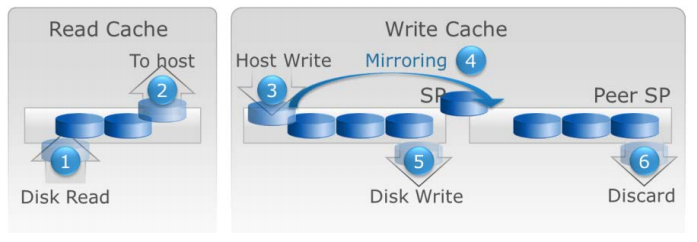
FLARE Cache 와는 다르게 Multicore Cache 에는 Read/Write Cache 가 분리되어있지 않습니다. Cache 는 Write(1)/Read(2) 를 위해 공유되며, 이것을 Adaptive Cache 라고 합니다. 물론 Write 가 Peer SP 로 Mirrored 되는 것은 동일합니다. 그리고 Dirty Cache page 가 Disk 로 Flushing 되는 것 대신에 디스크로 복제되게 되며(3), 메모리에 계속 남아있게 됩니다. 다시 Read(4)/Write Hit(5) 가 발생할 경우에 Flush 이 발생하지 않기 때문에(6) 성능이 향상됩니다. 다른 워크로드를 위하여 Page 가 초기화 될 때 데이터가 Cache 에서 삭제됩니다.(7)
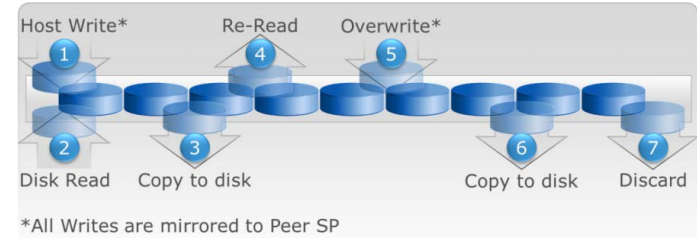
Mirroring 은 중요합니다. Dirty page 는 항상 Peer SP 의 Cache 로 Mirrored 되기 때문에 하나의 SP 가 죽더라도 남은 SP 에서 데이터의 복사본을 유지하게 됩니다. 이 경우 Peer SP 의 mirrored 된 page 는 dirty page 와 동일하게 됩니다. 다만 Owner 가 다릅니다. 두개의 SP 모두 자신이 가지고 있는 Page 와 Peer SP 가 가지고 있는 Mirrored Page 에 대한 Track 을 휴지하고 있습니다. Page Owner 는 한쪽의 SP 가 사용이 불가능 할때(패닉이 되었을 때나 Crash 또는 reboot 등) 변경되게 됩니다. 각각의 SP 는 자신이 가지고 있는 dirty page 를 백엔드로 플러싱하고, 각자의 Cache 의 Dirty flag 를 삭제해야 합니다.
Multicore Cache 는 모든 Cache page 에 대한 매우 상세한 통계정보를 유지하며, 이 정보들은 Page Aging 등에 사용되거나, 계속 증가합니다. 모든 성공한 Hit 는 Page 의 age 를 감소시키게 되며, 캐시에 좀 더 오래남을 수 있게 됩니다. 그 결과로 최근에 발생한 이벤트가 좀 더 중요한 것으로 간주되게 됩니다. 즉 지난달에 발생한 이벤트보다 1시간 전에 발생한 이벤트가 훨씬 더 중요하다는 것이죠.
Multicore Cache 로 인하여 Pools 을 사용하는데 많은 이점이 있습니다. Pool 은 Private RAID Group 들의 집합인데, 이러한 Private RAID Group 은 일반적인 RAID Group 는 다르게 사용자가 직접 제어할 일이 없게 되고 시스템에서 모두 관리하게 됩니다. Multicore Cache 가 Private RAID Group 내의 트래픽을 모니터하고 관리하기 때문에 사람이 할일이 없습니다.
Flushing
FLARE 는 Forced Flushing 이라는 것이 존재하는데, dirty cache page 의 퍼센트가 High watermark 에 도달하거나 100% 가 되었을 때 Forced Flushing 이 발생하게 됩니다. 이 경우 모든 디스크에 저장되지 않은 데이터(dirty) 가 disk 로 flushing 되고, 이 때 호스트 I/O 가 중단됩니다. 언제까지 중단되느냐, dirty cache page 의 퍼센트가 Low watermark 이하가 될때까지 Forced flushing 이 계속 됩니다. Forced flushing 은 스토리지 전체에 영향을 주게되며, 호스트의 응답시간이 엄청나게 증가하게 됩니다. Flushing 을 최우선적으로 처리하기 때문입니다. High 와 Low watermark 는 Forced Flushing 이 발생하지 않도록 하기 위해 시작되었으며, High Watermark 보다 퍼센트가 낮을 경우에는 Cache 의 버퍼를 증가시킴으로써 Forced Flushing 이 최대한 발생하지 않도록 합니다.
Dynamic Watermark
Mutlicore Cache 에서는 Cache 를 비우는 모델에 변화가 있었습니다. 기존의 Low 와 High watermark 는 더이상 존재하지 않으며, Dirty Cache page 의 트랙을 유지하는 것 뿐만 아니라, 해당 페이지가 참조하고 있는 LBA(Logical Block Address) 를 모니터링 하게 됩니다. 스토리지 시스템에서는 지속적으로 워크로드에 대하여 Cache 가 효율적으로 사용되고 있는지 측정합니다. 예를 들어, Write I/O 버퍼링은 짧은 시간의 Burst 에는 효율적이지만, 시스템 전체의 캐시공간을 사용하는 워크로드에는 효율적이지 않습니다. 앞에서 언급했던대로 Flushing 은 성능을 향상시키지 않으며 오히려 그 반대로 시스템의 모든 워크로드에 악영향을 미칩니다.
Multicore Cache 는 워크로드를 효율적으로 처리하게 위해 들어오는 I/O 의 비율을 측정하고, Private RAID Group 를 모니터링 합니다. 많은 dirty page 가 생기게 되는 write I/O 를 발생시키는 워크로드는 좀 더 많은 Cache 자원을 사용하게 될 것입니다. 시스템에서는 들어오는 Write I/O 비율과 RAID Group 에서 발생하는 page flushing 의 횟수의 차이를 계산합니다. 이러한 계산은 Mutlicore Cache 로 하여금 워크로드의 변화에 다이나믹하게 대응할 수 있게 하여 줍니다.
일단 오늘은 여기까지. 나중에 추가.