Part2 에서 다뤘던 CUDA 에 대해서 조금 더 알아보겠습니다. (아주 Deep 하게 들어가진 못합니다 저도 모르니까요)
GPGPU 에서는 데이터 처리를 하는 단위를 쓰레드(Thread)라고 부릅니다. 즉 하나의 GPU Core 가 하나의 쓰레드를 처리할 수 있다고 보면 됩니다.
100개의 쓰레드를 처리해야 한다면 100개의 코어가 있으면 아주 효율적으로 처리할 수 있겠죠. 그렇지만 실제로 처리해야할 양이, 즉 쓰레드의 숫자가 100만개, 1000만개가 되면 어떻게 될까요. 가장 최근의 GPU 인 H100(SXM5 폼펙터 기준) 의 CUDA core 숫자도 16,896개 밖에 안됩니다. 그리고 물리적인 코어 숫자를 무한정 늘릴수도 없죠.
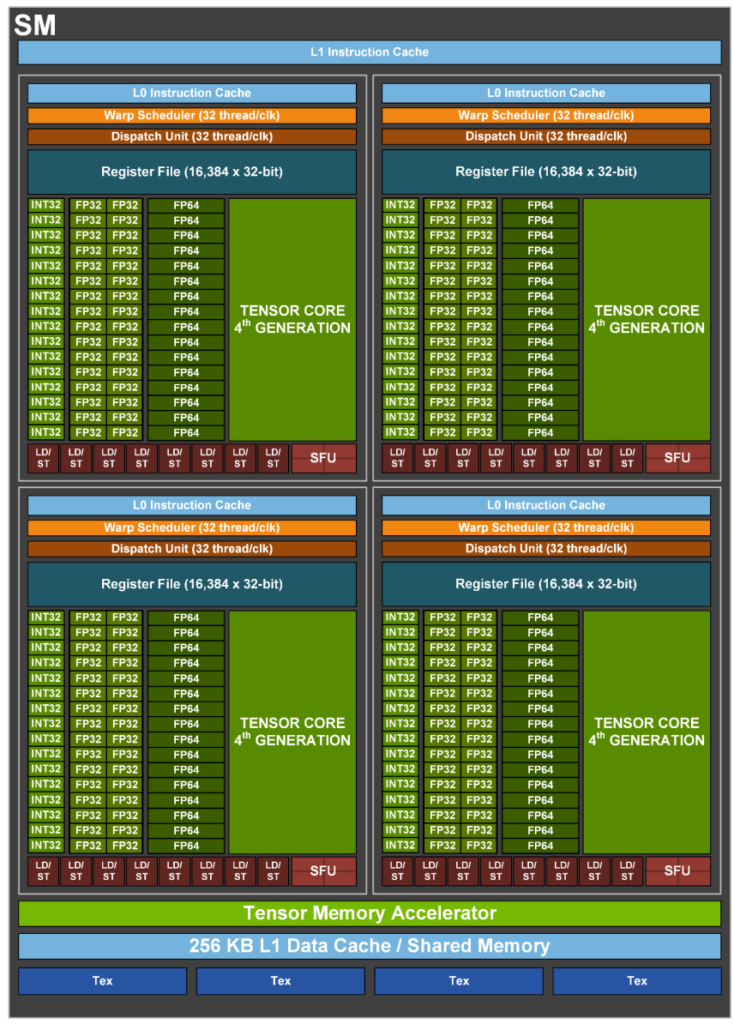
이때에는 100만개의 쓰레드를 여러개의 그룹으로 나누게 됩니다. 예를 들어 100개의 쓰레드를 하나의 그룹으로 묶어주면, 10,000개의 쓰레드 그룹이 나오게 되죠. 이런 쓰레드 그룹을 Warp 라고 부릅니다. 그래서 Warp 내의 100개 쓰레드들은 한개의 데이터 처리로 간주됩니다.즉 한개의 GPU Core 가 하나의 Warp 내의 100개의 쓰레드를 담당하게 되는 식입니다. 이러한 Warp 들을 GPU Core 에 할당하는 Warp 스케쥴러가 따로 존재하는데, 이게 GPU 내에서 발생하는 지연시간을 줄이는데 중요한 역할을 한다고 합니다.
위는 간단한 예를 들었지만, 실제로는 각 하드웨어의 코어 구성에 따라 Warp 내의 Thread 의 숫자도 달라져야 할 것입니다. H100 예를 위에서 들었으니까, H100 을 가지고 이야기 해보겠습니다.
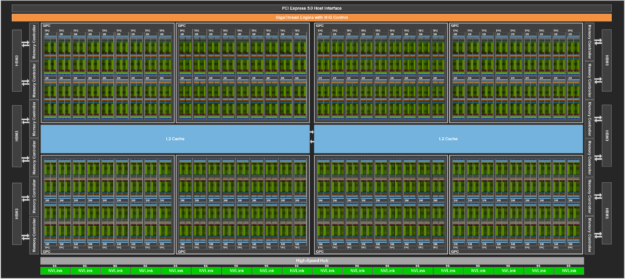
H100 with SXM5 폼펙터 카드의 경우, 대략 아래와 같은 스펙을 가지고 있습니다.
- 132 개의 SM(treaming Multiprocessors)
- SM당 128개의 CUDA Core => 128 x 132 = 총16,896개의 CUDA Core
- Warp 당 Thread 수 = 32
- SM 당 Max Warp 64
- SM 당 Max Thread = 32*64 => 2048
위 내용을 말로 풀어서 설명하면, 1개의 warp 내에 32개의 쓰레드가 하나의 연산처럼 수행된다 라고 볼 수 있는거죠.
잘은 모르지만 Deep Learning 에서는 신경세포를 흉내낸 신경망 네트워크(뉴럴 네트워크)를 사용한다고 합니다. 많은 데이터를 입력받고, 연산하여 결과값을 도출해 내는 형태라고 하네요. 근데 이게 뜯어보면, 곱하기와 더하기를 반복하는 단순한 구조라고 합니다. 그러다보니 GPU 를 활용하여 단순 연산을 수행하는 것이 효율적이라고 이야기를 하는 것입니다.
비트코인 채굴방식의 경우도, 정해진 해시값이 나올때까지 임의의 숫자를 계속 더하는 단순한 방식이기 때문에, 순차적으로 진행될 필요가 없고 병렬로 진행하는 것이 효과적입니다. 이 때문에 비트코인 채굴장에 GPU 들이 끌려가서 노동을 하는 것이죠.