제가 VMware 에 재직하는 동안 일종의 specialist 였던 분야가 VM sizing 이나 NUMA 에 대한 부분이였는데요, 막상 이곳 블로그에는 NUMA 관련된 글을 적은적이 없더군요. 내외부적으로는 세션도 많이하고 질의응답 및 관련 트러블슈팅도 많이 했었는데… 아마 옮겨 적을 엄두가 나지 않아서 그랬던게 아닌가 싶습니다.
물론 지금도 NUMA 의 어떤 부분에 대해서 적을 수 있을지는 잘 모르겠습니다…ㅋㅋ
Specialist 라고 적어두긴 했지만 사실은 깊게 들어가면 저도 잘 모르는거죠. 제가 이해하는 수준에서 적는건데, 아마 이해가 부족하여서 적을 엄두가 나지 않았던것 같습니다. 특히 오늘 이야기할 Sub NUMA Clustering (이하 SNC) 에 대해서는 대략적인 의미는 알겠는데, 상세한 내용에 대한 이해는 좀 부족했는데, 이 동네에서 유명한 양반중 한명인 Frank 가 마침 본인의 블로그에 상세한 내용을 올려놓아서 한번 읽어보았습니다. 그렇지만 저도 깊게 다루진 못하니까 이정도만 알면 되지 않을까 라는 내용으로 정리해보겠습니다. 만약 여건이 되시는분이라면 한번 정독 해보시는것도 좋을것 같습니다.
NUMA
NUMA (Non-Uniform Memory Access) 가 뭐냐를 한마디로 설명할 수 있을까요? 아님 알아들게 설명할 수 있는 멘트가 있을지 잘 모르겠습니다.. 오늘의 포스트에서는 가상화 환경에서의 NUMA 의 영향도(?) 에 서만 다루겠습니다. 그리고 Intel 에 대해서만, 그 이유는 최근의 AMD CPU 는 Multi-Chip-Module 구조이기 때문에 결이 많이 달라서 그렇습니다.
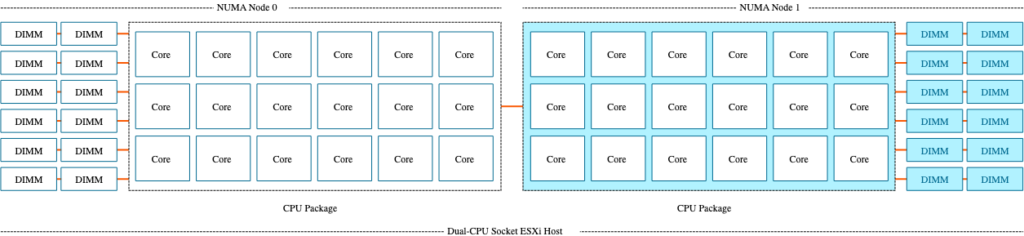
인텔의 네할렘 CPU 이후부터는 대체로 위와 같은 형태로 디자인 되어있는데요 (CPU 별로 메모리 컨트롤러/채널 이 존재하는 형태), 위 그림은 Skylake CPU 의 아키텍처입니다. (소켓당 6개의 메모리 채널이 존재하는) 두개의 CPU 를 연결하는 인터페이스를 UPI 라고 부릅니다. 그래서 각 소켓을 기준으로 봤을때, 자신의 메모리 컨트롤러에 연결되어있는 메모리는 Local Memory / 다른 소켓의 메모리 컨트롤러에 연결되어있는 메모리를 Remote Memory 라고 부릅니다.
위 그림만 보면 2소켓 18코어 CPU 네요. 두개의 경우를 가정해보겠습니다.
– 8vCPU VM
– 24vCPU VM
위와 같이 2개의 VM 이 있다고 하면, 8vCPU VM. 은 Numa Node 0 또는 1번에서만 실행될겁니다. 그리고 각 노드에 붙어있는 로컬 메모리에만 접근을 하겠죠. 그래야 가장 Memory Latency 를 줄일 수 있으니까요. 24vCPU 의 경우 한쪽 노드에서 전부 기동할 수 없음으로 12vCPU 씩 나눠져서 Numa Node 0번과 1번에서 실행되고, 각 소켓의 메모리 채널에서 메모리를 할당받을 겁니다. 그럼 로컬 메모리도 존재하고 리모트 메모리도 존재하는 형태가 됩니다. 이때 가장 좋은 성능을 낼려면, 리모트 메모리로의 액세스 보다는 로컬메모리로 액세스를 최대한 많이 해야 최적의 성능이 나오게 되는거죠. 이렇게 될려면, Hypervisor, Guest OS, Application 이 모두 이러한 NUMA 구조를 인지하고, 어디가 로컬이고, 어디가 리모트인지를 알아야 합니다. ESXi 의 경우는 NUMA 구조를 잘 이해하는 Hypervisor 라고 볼 수 있습니다.
위와 같이 VM sizing 에 따라 NUMA 로 인한 영향을 받을 수 있는 거죠. 이때 그럼 성능면에서 가장 좋은 VM Sizing 은 뭐라고 볼 수 있을까요? 제 생각으로는 Remote Memory 의 접근을 원천적으로 차단할 수 있는 사이징, 즉 단일 NUMA Node 안에 들어올 수 있는 크기로 사이징 하는것이 가장 좋다고 볼 수 있겠습니다. 또 이게 메모리에 대한 부분이다 보니까 메모리도 NUMA node 당 얼마의 메모리가 장착되어있는지를 고려 하셔야 겠죠. CPU 의 L3 Cache(LLC) 성능관점에서도 더 유리하고, 리모트 메모리 접근을 하지 않으니 메모리 레이턴시에도 가장 유리한 VM Sizing 이라고 할 수 있습니다. 그렇지만 경우에 따라 정말 큰 VM Sizing (Monster VM) 을 해야하는 경우도 생기기 때문에, 반드시 고수해야할 원칙이라고는 말할 수 없습니다. 가능하다면 그러는게 좋다는 거죠.
SNC (Sub NUMA Clustering)
그럼 SNC 는 뭐냐, SNC 는 1개의 NUMA Node 를 2개의 NUMA Node 로 쪼개는 것입니다. 이게 BIOS 상에서 셋팅하는 설정인데, 대부분은 디폴트로는 Disable 되어있지만, 제 기억으로는 HPE 서버의 경우 BIOS 설정에서 Max performance 로 설정하면, SNC 가 켜집니다. 그것때문에 문제가 된 경우도 있고요.
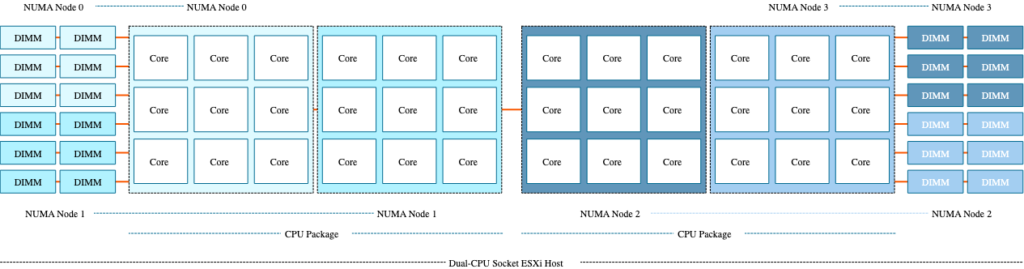
물리 CPU 는 두개인데, 시스템에서 인식하는 NUMA Node 의 숫자는 4개가 되는것입니다. 이렇게 해서 얻는 이점이 뭐가 있을까요? SNC 를 사용하게 되면 , Cache miss 발생시에 메모리에서 데이터를 가져오는 경우 발생하는 메모리 레이턴시를 최대 7% 정도 줄일 수 있다고 합니다.
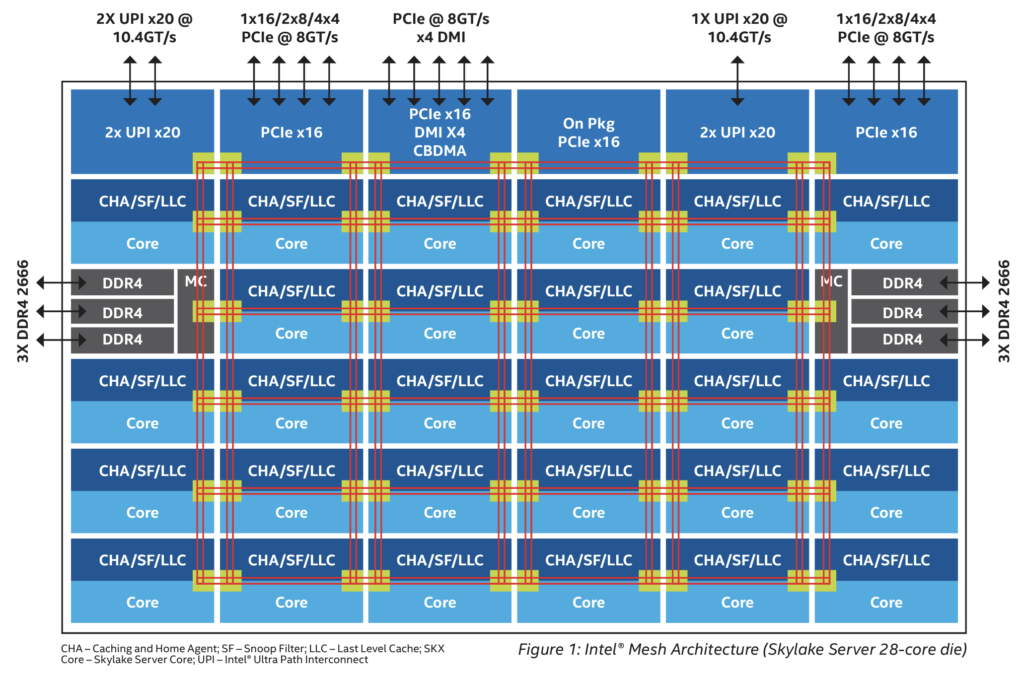
위 그림에 SNC 가 켜지게 되면, 절반을 딱 나누어서 각각의 NUMA domain 이 되는거죠. 그래서 각 도메인 마다 로컬로 간주되는 코어/LLC/메모리 컨트롤러/채널이 생기게 됩니다. LLC 의 경우는 원래 모든 코어가 쉐어하기 때문에, SNC 가 켜지게 되면, 이것도 절반으로 나눠지게 됩니다. 그럼 예를 들어, Node 0 번의 LLC 에 데이터가 없을 경우(Cache miss 인 경우)에는 Node 0번에 할당된 메모리 컨트롤러/채널로 가서 데이터를 가져오도록 하겠죠. 이때 데이터가 있다면 가장 best case 라고 할 수 있겠습니다. 만약 거기도 없다고 하면, Node1번 (같은 소켓에 있는) 에서 가져오게 될것이고 요거는 good case 정도라고 볼 수 있겠죠. 만약 거기도 없다고 하면 Node 2번/3번 (다른 소켓에 있는) 메모리에서 가져와야 하는데 이때가 bad/worst 케이스라고 볼 수 있을 것입니다. SNC 를 켜서 데이터를 검색해야 하는 단위를 더 쪼개고, 거기서 데이터를 가져오게 되면 데이터를 찾는 시간이 줄어들게 됨으로 가장 좋은 성능을 낼 수 있는것이죠 (운이 좋다면)
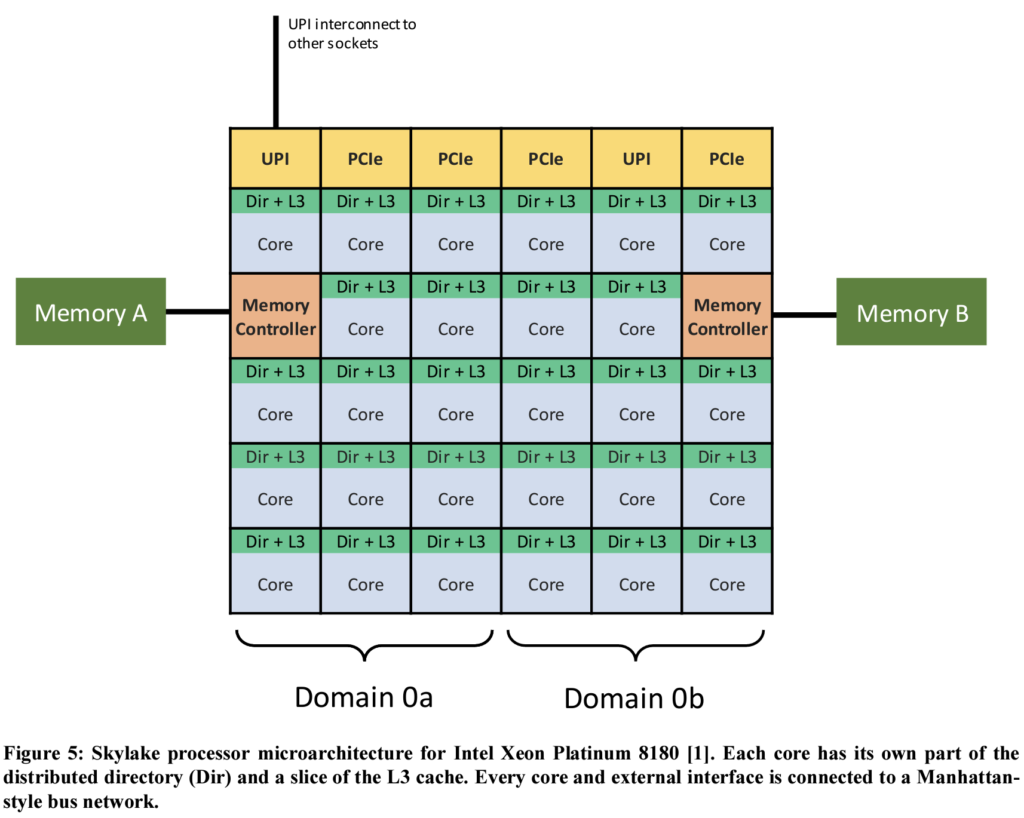
Frank 의 블로그 게시물을 보면, SNC 가 켜져있을 때와 꺼져있을때를 비교한 경우의 메모리 레이턴시는 다음과 같습니다.
| Memory Latency(ns) | SNC off | SNC on |
| Best | 79.9 | 74.2 |
| Worst | 139.7 | 144.5 |
즉 SNC, 를 사용했을때 가장 좋은 케이스에서는 7% 정도 메모리 레이턴시가 감소하지만, 안좋을때는 SNC를 사용하지 않을때보다 메모리 레이턴시가 더 안좋아진다는 것입니다. (4~5% 가량), 좋을때의 향상폭이 좀 더 크다고 느끼실수 있는데요, 문제는 가상화 환경에서는 다양한 사이즈의 workload 들이 실행된다는 것입니다. VM sizing 이 적절하지 않은 경우 worst 가 발생할 수 있는 여지가 좀 더 크다고 볼 수 있는거죠. 메모리 레이턴시 말고 Bandwidth 에 대해서도 이야기 했는데요, 결론은 비슷합니다.

어찌보면 위의 부분이 Haswell / Broadwell에서 사용하던 COD (Cluster-on-Die) 보다 SNC 로 변경이 되면서 가장 크게 개선이 된 부분이라고 볼수도 있겠네요. 초록색으로 표시된 Local NUMA node-9threads 와 보라색으로 표시된 Remote to same socket 의 Memory bandwidth 차이가 거의 없죠. 이전 COD 에서는 거의 50% 가까운 bandwidth 차이가 발생했었습니다. Remote to same socket 이나 Remote to other socket 이나 거의 차이가 없는 수준이였지만, SNC 로 변경되면서 해당 부분이 개선이 되었다고 볼 수 있겠습습니다.
만약 2소켓 18cores 환경에서 SNC 를 켜놓고 10 vCPU 짜리 VM 를 돌린다면, 두개의 NUMA Node 에 걸쳐서 실행이 되어야 합니다. 그리고 이러한 구조를 VM 에 노출시켜줘야 하기 때문에 vNUMA 도 실행됩니다. 문제는 NUMA Node 가 각각 Socket 0 (NUMA Node 0,1) Socket 1(NUMA Node 2,3) 이렇게 되어있는데, (0,1) 또는 (2,3) 에 걸쳐서 실행되면 다행이지만, 경우에 따라 (0,3) (1,2) 에 걸쳐서 실행될 수 있기 때문입니다. 그렇게 되면? 리모트 메모리 액세스 발생 빈도가 더 높아지는거죠. NUMA Scheduler 에 의해서 VM 들이 배치될때는 NUMA Node 간의 거리를 감안하여 가급적 (0,1) 또는 (2,3) 이렇게 실행되어서 좋은 조건이 되는데,
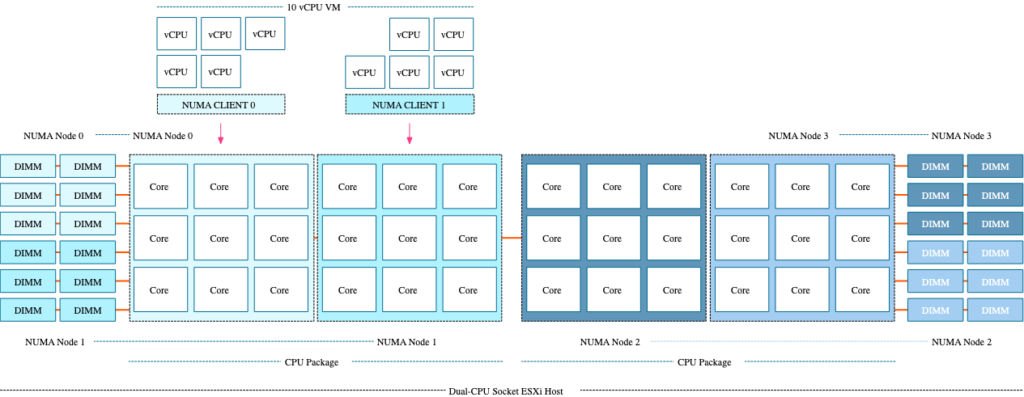
문제는 경합 발생등으로 인해 NUMA 노드간 Load Balancing 이 이루어질 때는, NUMA Node 간의 거리를 고려하지 않기 때문에 아래와 같은 경우가 발생할 수 있습니다.
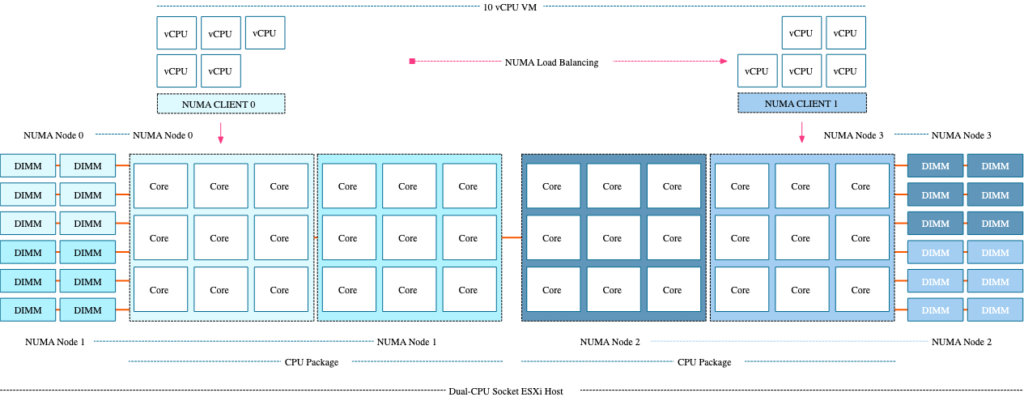
이게 다 SNC 가 켜져있어서 발생하는 문제이기 때문에, SNC 가 꺼져 있는 환경에서는 위와 같은 일이 발생하지 않는거죠. SNC 가 켜져있는 경우 위와 같은 케이스의 발생할 수 있는 확률이 높기 때문에, 뭔가 이상하다 하면 esxtop 을 통해서 어떤 numa node 에서 실행되고 있는지 꼭 확인해보시기 바랍니다.
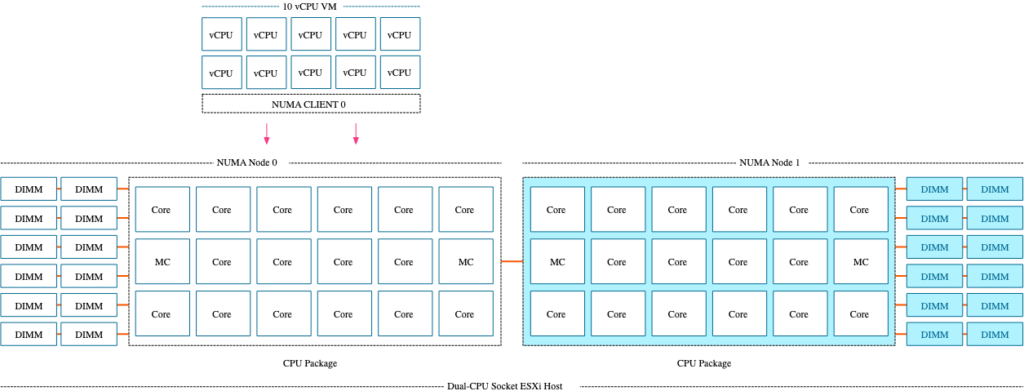
따라서 Frank 는 개인의 사견이라는 전제하에 다음과 같은 결론을 냈습니다.
SNC 를 사용할려면 VM Sizing 을 최대한 단일 NUMA node 안에 맞춰야 한다. (위의 18cores CPU 예라면 VM 의 크기가 9vCPU 를 넘기면 안됩니다. SNC 사용시 9개의 코어를 가진 2개의 NUMA Node 가 생성됨으로) 따라서 최대한 성능을 짜낼 수 있도록 튜닝된 workload 를 돌리는데 사용하면 좋다. (VOIP 나 증권거래 등.. 매우 낮은 레이턴시에 대한 요구조건이 있는경우) 그렇게 빡세게 튜닝된 환경과 workload 에서 SNC 를 쓰면 안쓸때보다 메모리 레이턴시는 7%, bandwidth 는 4% 좋아질 수 있다 이고, 그 외의 환경에서는 worst case 가 나올 수 있는 확률이 더 크기 때문에, 왠만하면 SNC 를 켜놓고 쓰지 마라.. 가 결론이라고 볼 수 있습니다.
In essence, It is my opinion that SNC is for the highly optimized, well-curated environment that has exploited every single trick in the book. It should not be the starting point for every virtualization platform.
Frank Denneman
그리고 요새는 GPU 나 NIC 등도 이러한 NUMA 구조의 영향을 받을 수 있기 때문에, 이러한 디바이스를 쓰실때에도 SNC 는 사용하지 않으시는게 좋겠습니다. CPU 와 GPU 가 각각 다른 NUMA domain 에 위치할 수 있기 때문입니다..
좋은 글이네요!
어려운 내용인데 쉽게 적어주셔서 정말 잘 읽었습니다.
도움이 되었다면 다행입니다.