기존의 ESXi 의 CPU Scheduler 는 Intel CPU 에 주로 포커싱이 되어있었는데요, AMD 의 EPYC 프로세서에는 기존에 완전히 대응하지 못해서, 상대적으로 성능면으로 불리한 부분이 있었습니다.
가장 큰 차이는 CPU 설계의 차이, 주로 NUMA 관련된 구조가 다르기 떄문입니다.
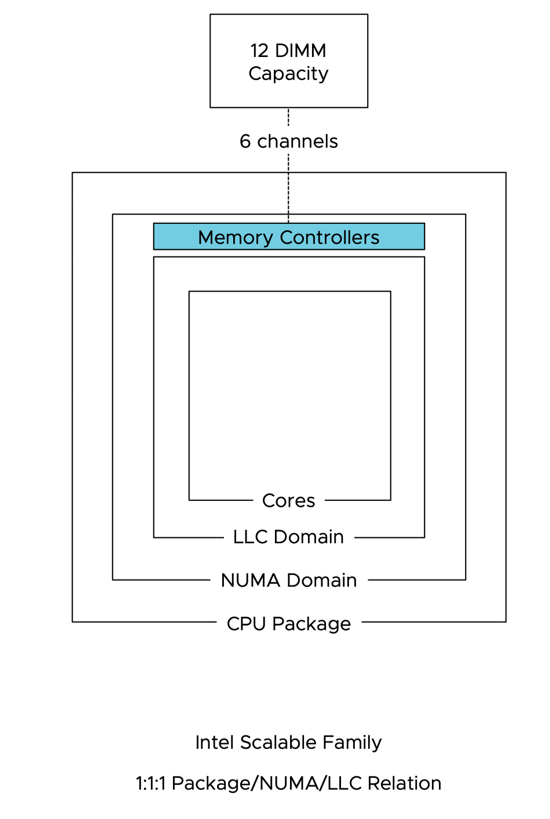
인텔 CPU 의 경우 소켓당 NUMA 도메인이 1개로, LLC 도 1개로 구성됩니다.
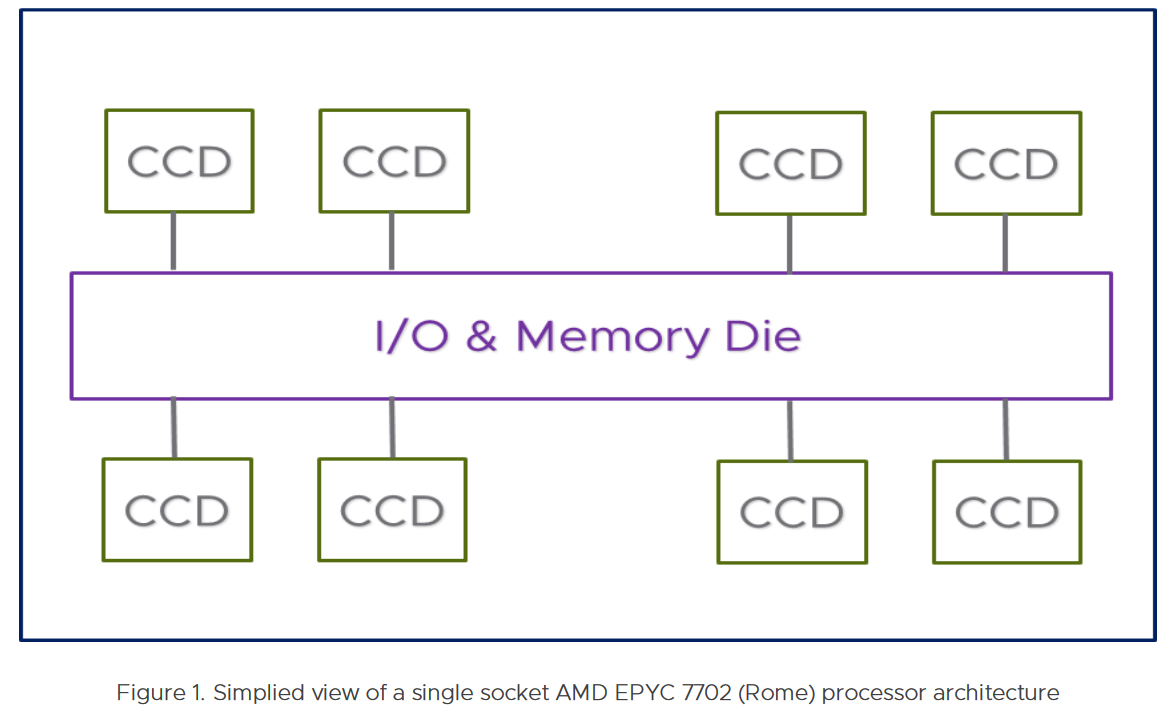
반면 AMD EPYC 의 경우 MCM(Multi-Chip Module) 구조로 되어있습니다. 세대별로 조금 차이는 있습니다만, 7002 (Rome) 프로세스의 경우 최대 8개의 CCD(Core Complex Dies) 가 Infinity Fabric 을 공유하는 형태로 되어있습니다.
그리고 각 CCD 는 2개의CCX 로 구성되는데, CCX 는 N개의 Cores 와 L3 캐시로 구성되어있습니다.
CPU 마다 차이는 있겠습니다만, 가장 많은 코어를 가진 7702 나 7742 프로세스의 경우, 소켓당 최대 64코어를 제공하고, 이 경우 CCX 는 4 Cores + 16MB 의 L3 Cache 가 제공됩니다.

그렇다면 CCD 는 2개의 CCX 로 구성됨으로, 위 예에서는 CCD 당 8개의 Cores 와 2개의 16MB L3 Cache 가 제공되는 것이죠. CCD 의 개수가 최대 8개임으로,
소켓당 최대 64 Cores 과 16개의 16MB L3 Cache (256 MB) 가 제공되는 것으로 보면 되겠습니다. 인텔에 비해서 상당히 많이 제공한다고 볼 수 있죠. 그렇지만 상대적으로 구조가 복잡하기 때문에 EPYC 프로세스를 위한 최적화 작업이 그동안 되지 않았었습니다.
vSphere 7.0U2 버전에 되서야, EPYC 프로세서를 위한 CPU Scheduler 개선이 이루어졌습니다.
기존에는 이러한 구조를 이해하지 못하기 때문에.. VM 이 아래와 같은 형태로 배치되는 경우가 있었습니다.
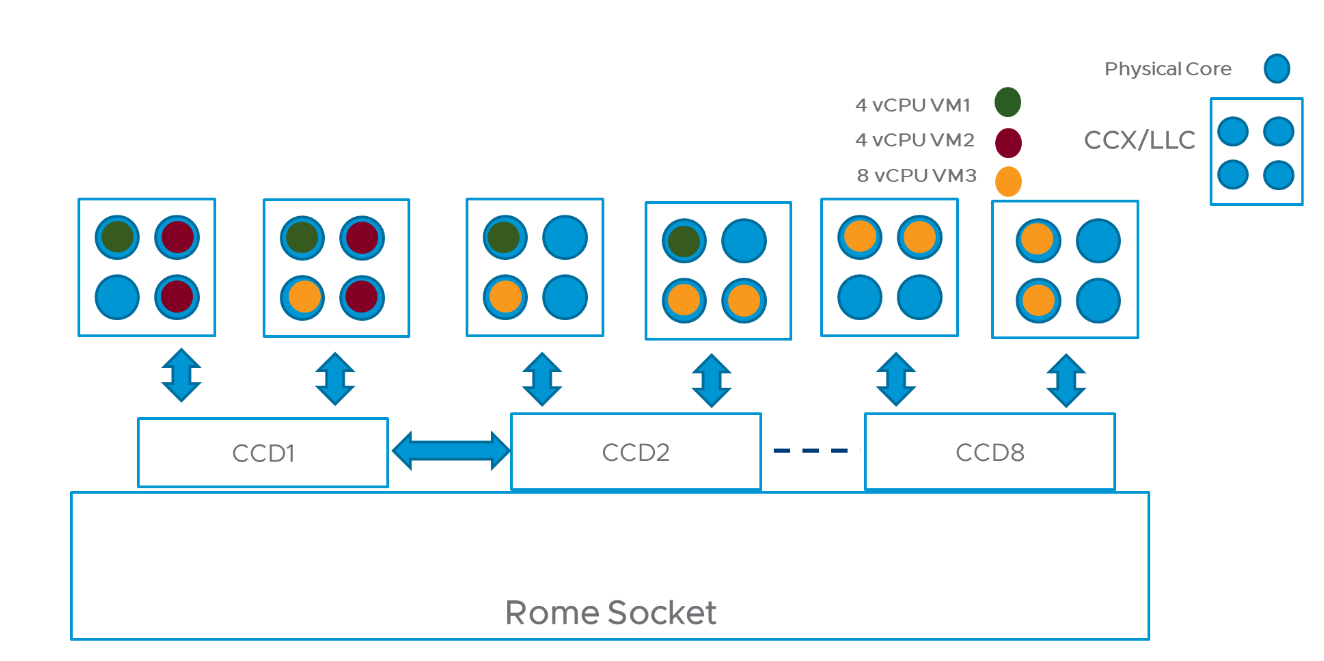
위 경우를 보게 되면, 1개의 VM 이 여러개의 CCX 로 분산되서 배치되는 것을 볼 수 있습니다. 이 경우 L3 Cache (LLC) 를 공유하지 않기 때문에, LLC 히트률이 떨어져서 성능이 제대로 안나오는 경우가 발생합니다.
VM1 은 4개의 LLC 로 분산, VM3 은 5개의 LLC 로 분산되는 것을 볼 수 있죠. 이 경우 다수의 VM 이 동일한 LLC 를 공유하기 때문에 발생되는 Cache contention 이나 Pollution 문제도 발생할 수 있습니다.
이러한 문제를 조치하기 위하여 AMD 시스템에서는 NPS(Numa per Socket) 설정 또는 CCX-as-NUMA 설정을 사용할 수 있었습니다. 다만 CCX-as-NUMA 의 경우 소켓당 NUMA node 가 16개가 되기 때문에 Large VM 에서는 썩 좋지 않습니다..
7.0U2 버전에서는 위 예가 아래와 같이 개선됩니다.
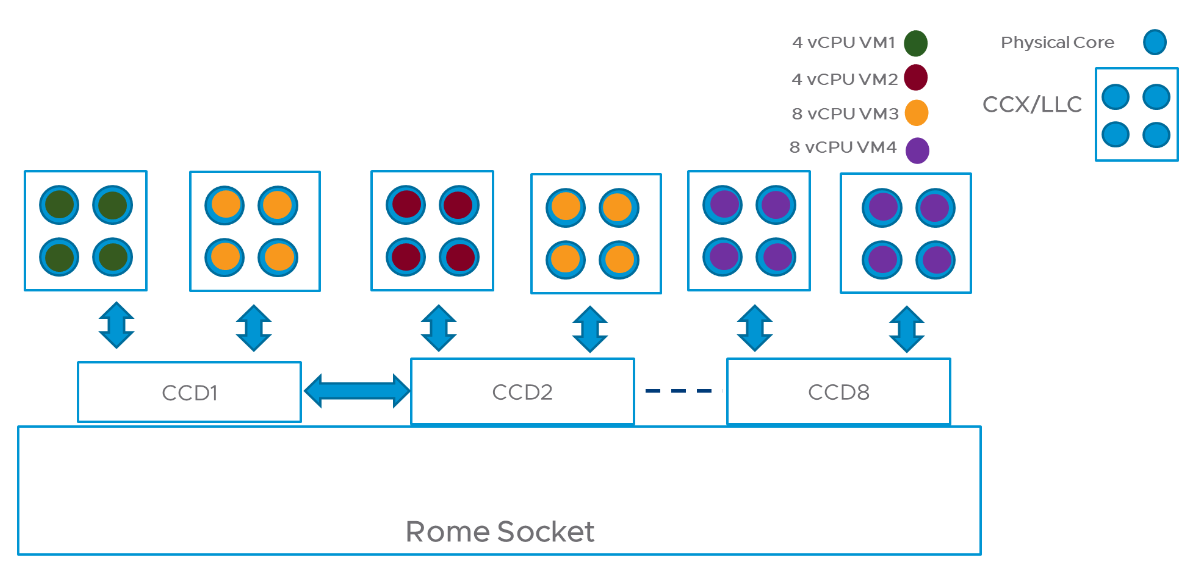
위 경우 VM3 번이 다른 CCD로 분산배치되긴 했지만, 그래도 대체로 양호하게 배치된것으로 볼 수 있습니다. 그런데 VM3 도 같은 CCD 로 배치할 수 있었을텐데, 왜 그렇게 안됐을까요? 그것은 위와 같은 CCD/CCX 구조가 OS 로 완전히 노출되지 않기 때문입니다. 따라서 현재의 CPU Scheduler 는 CCD 는 감안하지 않습니다. (This is due to the lack of topology information exposed by the hardware (to operating systems) that describes the difference between CCX and CCD. The vSphere CPU scheduler will not try to place them on the same CCD, even though peak performance may be achieved if they are placed on the LLCs that are on the same CCD.)
그렇다면 위와 같은 문제는 어떻게 개선되었느냐? EPYC 프로세서의 경우 3세대 Milan 에서 CCD/CCX 구조를 변경함으로써 개선되었습니다. (CCD 당 2개의 CCX 가 아닌 CCD 당 1개의 CCX 구조로 변경)

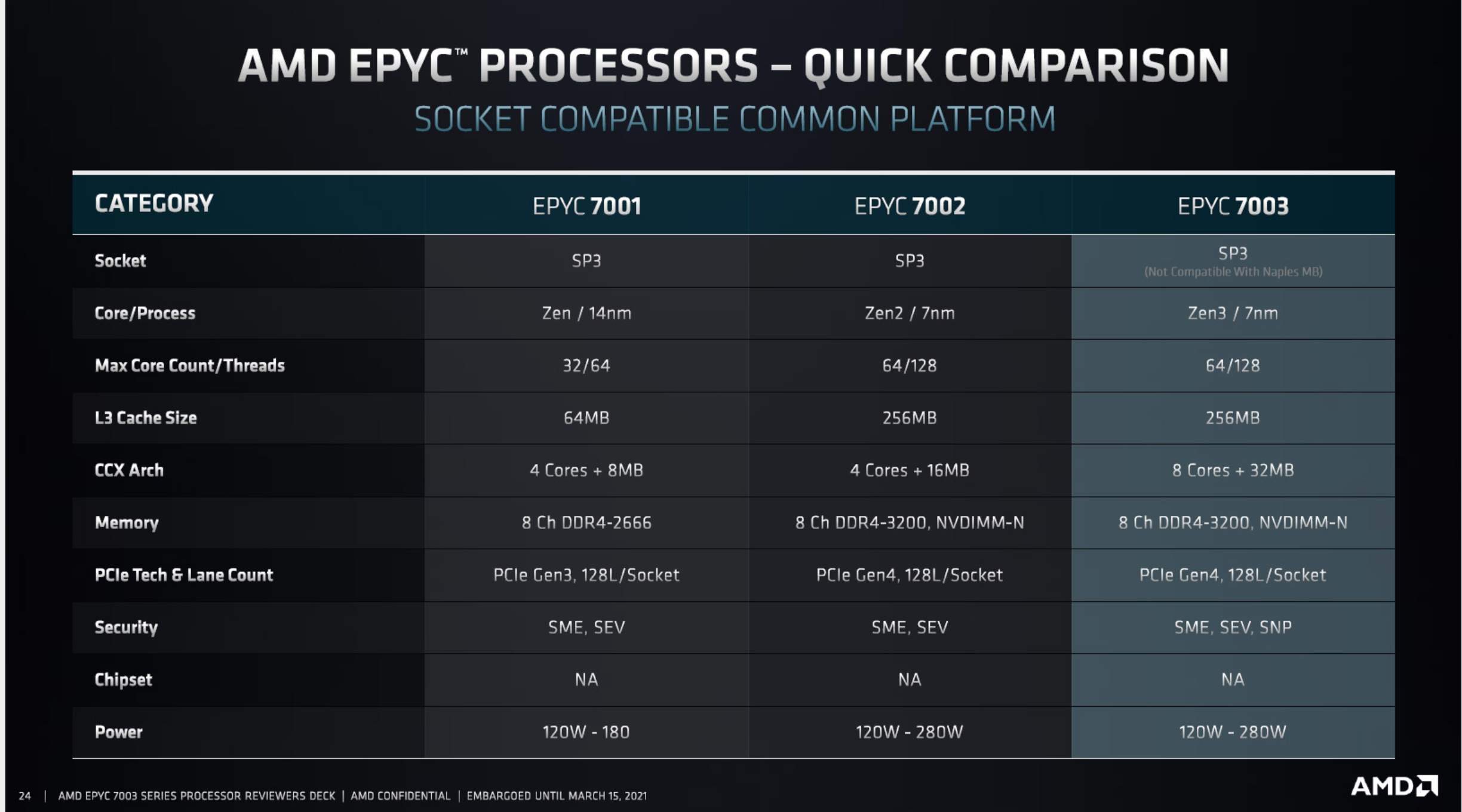
두번째 스크린샷을 보시면 CCX Arch 항목이 변경된것을 볼 수 있죠.
아무튼 요약하면 AMD EPYC 를 쓰시는 경우에는 7.0U2 이상 버전으로 업그레이드를 꼭 하십시요.