vSphere 8 CPU Topology for Large Memory Footprint VMs Exceeding NUMA Boundaries – frankdenneman.nl
위 게시물을 제가 개인적으로 이해한바로 해석한것이니 참고 부탁드립니다. (This is my understanding of Frank’s post)
vSphere 7 버전까지는 NUMA 도메인의 크기내에 들어오도록 vCPU 할당을 하면 vNUMA 가 동작하지 않고, NUMA 도메인의 크기를 벗어나게 vCPU 할당을 하면 vNUMA 가 동작하였습니다. 그러니까, vNUMA 가 동작하는 조건에는 메모리의 크기는 고려하지 않고 vCPU 의 숫자만 카운트 했다는 이야기 입니다.
일반적으로 국내의 경우 대용량(Monster or Wide) VM 이라고 보면 vCPU 도 많이, 메모리도 많이 할당하기 때문에, 적은 vCPU 와 많은 메모리의 구성을 잘 하지 않죠.. 왜냐고 물어보신다면, 제 개인적으로는 “CPU 적게 줬다가 성능 안나오면 니가 책임질꺼야?” 라는 말을 많이 들었던것 같네요. -.-
암튼 앞에건 잡담이였고, 위의 경우 vCPU 의 갯수는 NUMA 도메인내로 들어오지만(또는 vCPU 가 9개 미만인경우) 할당한 메모리는 클 경우에, 별다른 설정을 하지 않은 경우에는 한쪽 NUMA 도메인의 메모리를 모두 할당해버립니다.
예를 들어, NUMA Domain 당 256GB, Total 512GB 의 시스템에서, 384GB 의 메모리를 VM 에다가 할당하게 되면, 우리가 원하는 것은 대부분 192GB/192GB 로 잘 분배되어서 할당되길 원하지만, 실제로는 256GB/128GB 로 할당이 된다는 것입니다. (실제로는 NUMA memory scheduler 에 의헤 좀 더 다이나믹 합니다만, 예를 들어 그렇다는 것입니다.)
이 문제를 해결하기 위해 사용하던 옵션이 “numa.consolidate = FALSE” 입니다.
이 옵션을 사용하면, 메모리를 균등하게 할당해줍니다. 그러나 이것을 사용하더라도, Guest OS 에서는 여전히 본인의 NUMA Domain 은 1개라고 인식하기 때문에, 위 옵션을 사용함으로써 얻어지는 이점은 호스트 레벨에서의 NUMA Scheduler 만 있습니다.
이 옵션 외에도 사용할 수 있는게 강제로 vNUMA 동작 조건을 바꿔주는것입니다.(numa.vcpu.maxPerVirtualNode), 만약 메모리 퍼포먼스가 더 중요하다면 이 옵션도 고려해볼 수 있습니다.
vSphere 8 에서는 위 문제를 해결할 수 있는 옵션들을 UI 상에서 제공한다고 합니다.
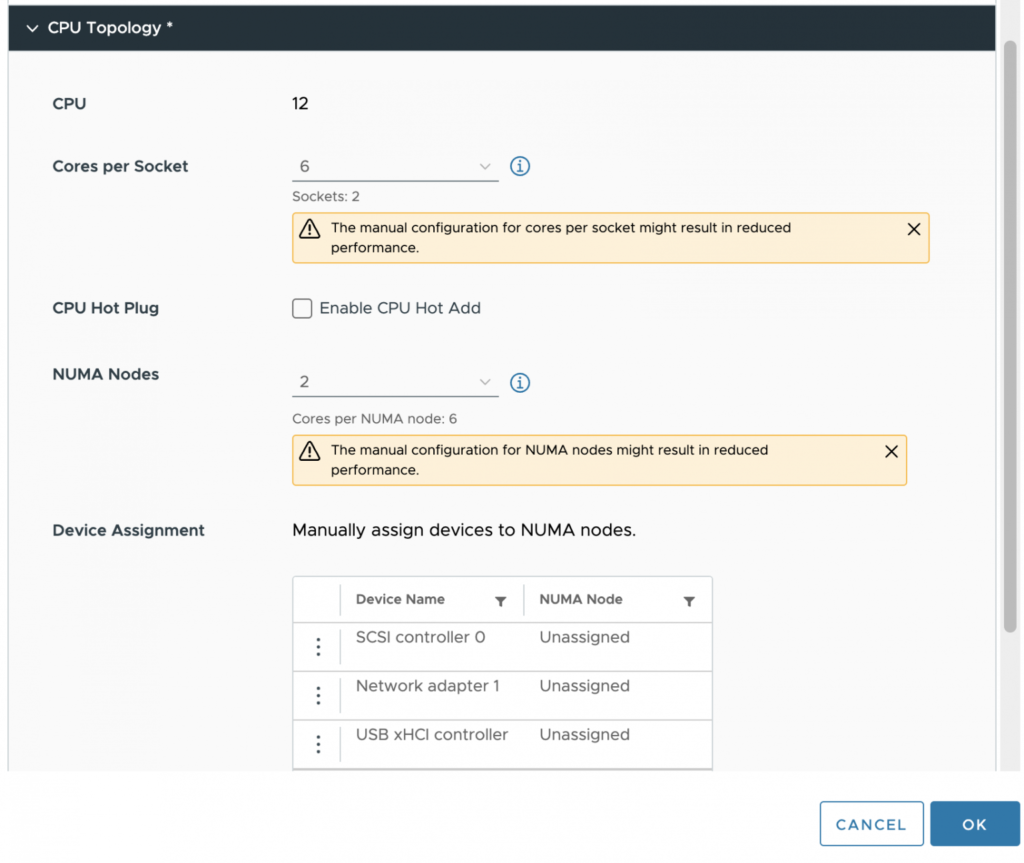
위 예에서는 2 sockets 40 cores / Total 512GB 메모리를 가진 호스트에서, 12vCPU 에 384GB 메모리를 할당한 VM 을 만들경우를 보여주고 있습니다. vCPU .가 12개 이기 때문에 기본적으로는 NUMA Node 가 1개가 되죠. 이렇게 할당하게 되면, VM 의 입장에서는 본인에게 할당받은 메모리 384GB 가 단일 NUMA Node 에 있는것으로 인식하기 떄문에, Local 와 Remote 메모리를 구분하지 못합니다. 그래서 성능저하 문제가 생기죠.
vSphere 8 에서는 위 그림에서 보시는 바와 같이, Cores per socket 수치를 조정하여 VM 상에서 2 socket 으로 인식하도록 만들어 주고(이건 기존에도 있기는 했었습니다만), 거기에 + 로 NUMA Nodes 숫자까지 2로 바꿔줌으로써, 원래 20 cores 이던 단일 NUMA 도메인의 크기를 6 cores 로 조정함으로써, vNUMA 가 동작하도록 할 수 있게 해주는 것입니다.
이 모든것을 해야하는 이유는 결국은 VM 의 vCPU/Memory 토폴로지를 물리 Physical 구성과 유사하게 만들어주는 것입니다. 그래야 잘못된 CPU Topology 로 인한 성능저하를 막을 수 있습니다.